Chapter 13: @merge multiple input into a single result¶
See also
Overview of @merge¶
The previous chapter explained how Ruffus allows large jobs to be split into small pieces with @split and analysed in parallel using for example, our old friend @transform.
Having done this, our next task is to recombine the fragments into a seamless whole.
This is the role of the @merge decorator.
@merge is a many to one operator¶
@transform tasks multiple inputs and produces a single output, Ruffus is again agnostic as to the sort of data contained within this single output. It can be a single (string) file name, an arbitrary complicated nested structure with numbers, objects etc. Or even a list.
The main thing is that downstream tasks will interpret this output as a single entity leading to a single job.
@split and @merge are, in other words, about network topology.
Because of this @merge is also very useful for summarising the progress in our pipeline. At key selected points, we can gather data from the multitude of data or disparate inputs and @merge them to a single set of summaries.
Example: Combining partial solutions: Calculating variances¶
The previous chapter we had almost completed all the pieces of our flowchart:
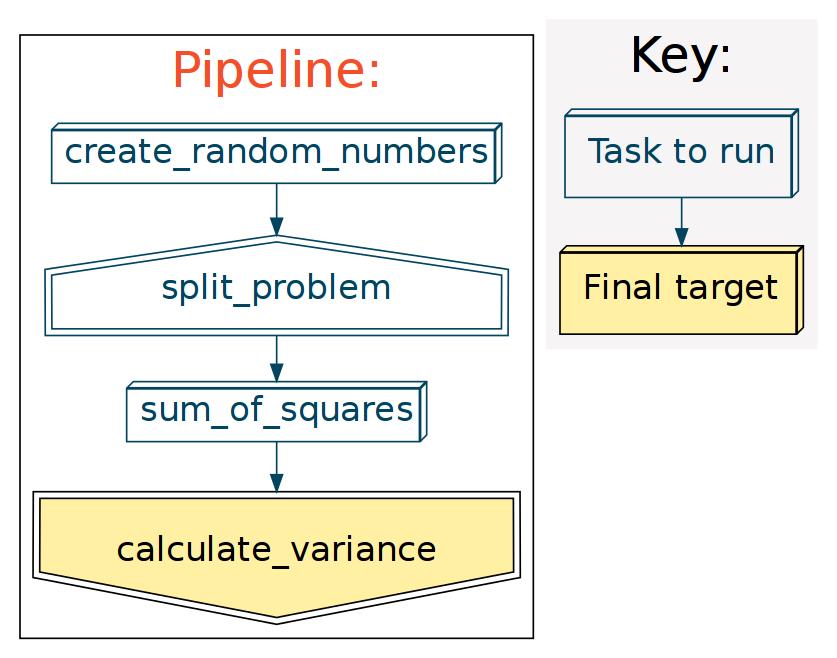
What remains is to take the partial solutions from the different
.sumsfiles and turn these into the variance as follows:variance = (sum_squared - sum * sum / N)/Nwhere
Nis the number of valuesSee the wikipedia entry for a discussion of why this is a very naive approach.
To do this, all we have to do is iterate through all the values in
*.sums, add up thesumsandsum_squared, and apply the above (naive) formula.# # @merge files together # @merge(sum_of_squares, "variance.result") def calculate_variance (input_file_names, output_file_name): """ Calculate variance naively """ # # initialise variables # all_sum_squared = 0.0 all_sum = 0.0 all_cnt_values = 0.0 # # added up all the sum_squared, and sum and cnt_values from all the chunks # for input_file_name in input_file_names: sum_squared, sum, cnt_values = map(float, open(input_file_name).readlines()) all_sum_squared += sum_squared all_sum += sum all_cnt_values += cnt_values all_mean = all_sum / all_cnt_values variance = (all_sum_squared - all_sum * all_mean)/(all_cnt_values) # # print output # open(output_file_name, "w").write("%s\n" % variance)This results in the following equivalent function call:
calculate_variance (["1.sums", "2.sums", "3.sums", "4.sums", "5.sums", "6.sums", "7.sums", "8.sums", "9.sums, "10.sums"], "variance.result")and the following display:
>>> pipeline_run() Job = [[1.sums, 10.sums, 2.sums, 3.sums, 4.sums, 5.sums, 6.sums, 7.sums, 8.sums, 9.sums] -> variance.result] completed Completed Task = calculate_varianceThe final result is in
variance.resultHave a look at the complete example code for this chapter.