Chapter 11: Pipeline topologies and a compendium of Ruffus decorators¶
See also
Overview¶
Computational pipelines transform your data in stages until the final result is produced.
You can visualise your pipeline data flowing like water down a system of pipes. Ruffus has many ways of joining up your pipes to create different topologies.
Note
The best way to design a pipeline is to:
- Write down the file names of the data as it flows across your pipeline.
- Draw lines between the file names to show how they should be connected together.
@transform¶
So far, our data files have been flowing through our pipelines independently in lockstep.
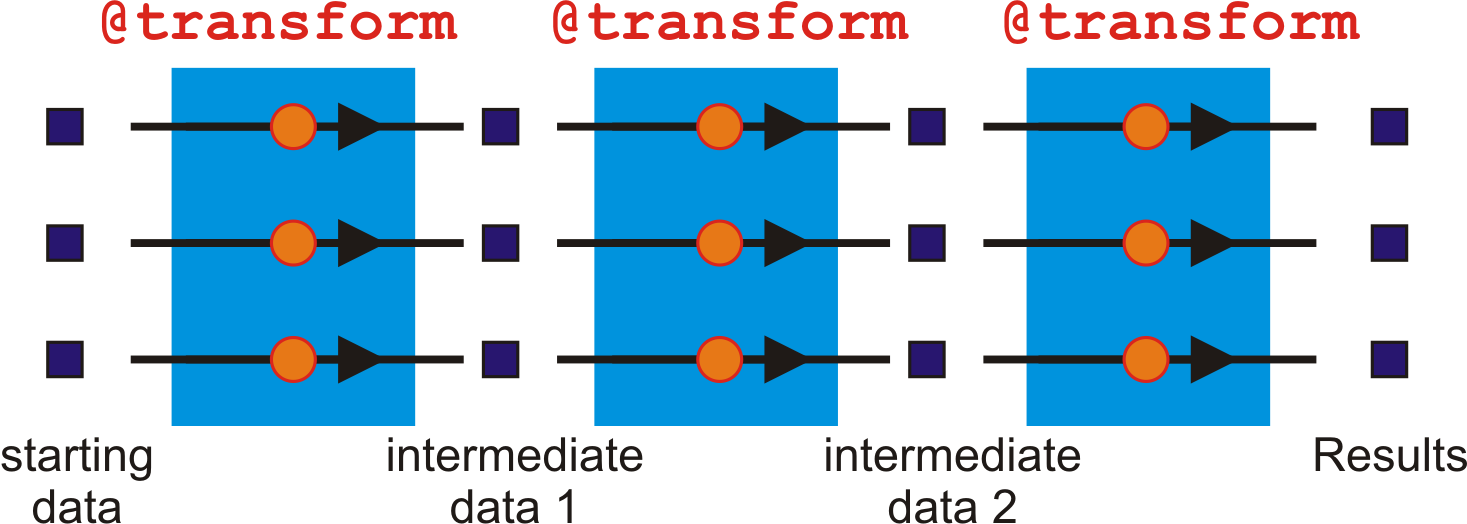
If we drew a graph of the data files moving through the pipeline, all of our flowcharts would look like something like this.
The @transform decorator connects up your data files in 1 to 1 operations, ensuring that for every Input, a corresponding Output is generated, ready to got into the next pipeline stage. If we start with three sets of starting data, we would end up with three final sets of results.
A bestiary of Ruffus decorators¶
Very often, we would like to transform our data in more complex ways, this is where other Ruffus decorators come in.
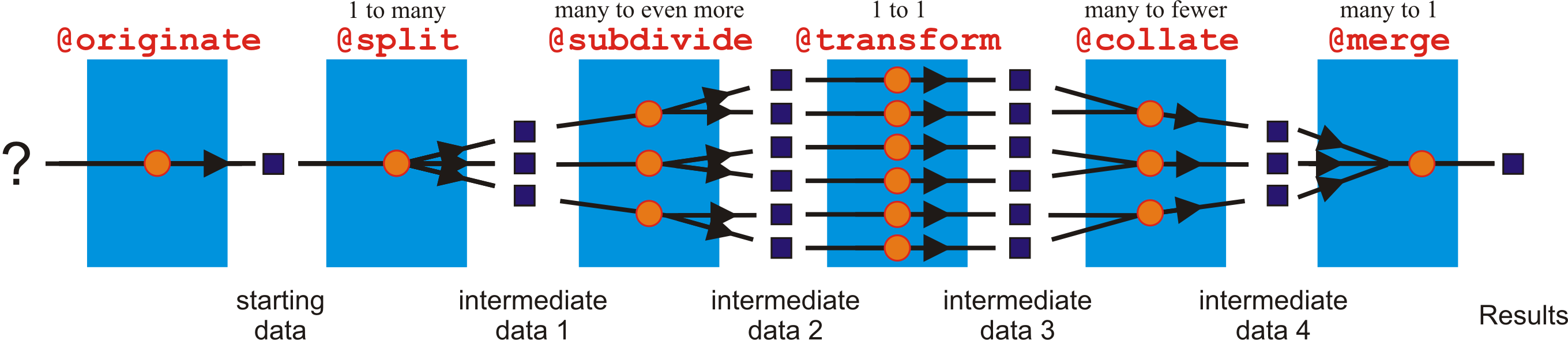
@originate¶
- Introduced in Chapter 3 More on @transform-ing data and @originate, @originate generates Output files from scratch without the benefits of any Input files.
@merge¶
- A many to one operator.
- The last decorator at the far right to the figure, @merge merges multiple Input into one Output.
@split¶
- A one to many operator,
- @split is the evil twin of @merge. It takes a single set of Input and splits them into multiple smaller pieces.
- The best part of @split is that we don’t necessarily have to decide ahead of time how many smaller pieces it should produce. If we have encounter a larger file, we might need to split it up into more fragments for greater parallelism.
- Since @split is a one to many operator, if you pass it many inputs (e.g. via @transform, it performs an implicit @merge step to make one set of Input that you can redistribute into a different number of pieces. If you are looking to split each Input into further smaller fragments, then you need @subdivide
@subdivide¶
- A many to even more operator.
- It takes each of multiple Input, and further subdivides them.
- Uses suffix(), formatter() or regex() to generate Output names from its Input files but like @split, we don’t have to decide ahead of time how many smaller pieces each Input should be further divided into. For example, a large Input files might be subdivided into 7 pieces while the next job might, however, split its Input into just 4 pieces.
@collate¶
- A many to fewer operator.
- @collate is the opposite twin of
subdivide: it takes multiple Output and groups or collates them into bundles of Output.- @collate uses formatter() or regex() to generate Output names.
- All Input files which map to the same Output are grouped together into one job (one task function call) which produces one Output.
Combinatorics¶
More rarely, we need to generate a set of Output based on a combination or permutation or product of the Input.
For example, in bioinformatics, we might need to look for all instances of a set of genes in the genomes of a different number of species. In other words, we need to find the @product of XXX genes x YYY species.
Ruffus provides decorators modelled on the “Combinatoric generators” in the Standard Python itertools library.
To use combinatoric decorators, you need to explicitly include them from Ruffus:
import ruffus from ruffus import * from ruffus.combinatorics import *
@product¶
- Given several sets of Input, it generates all versus all Output. For example, if there are four sets of Input files, @product will generate
WWW x XXX x YYY x ZZZOutput.- Uses formatter to generate unique Output names from components parsed from any parts of any specified files in all Input sets. In the above example, this allows the generation of
WWW x XXX x YYY x ZZZunique names.
@combinations¶
- Given one set of Input, it generates the combinations of r-length tuples among them.
- Uses formatter to generate unique Output names from components parsed from any parts of any specified files in all Input sets.
- For example, given Input called
A,BandC, it will generate:A-B,A-C,B-C- The order of Input items is ignored so either
A-BorB-Awill be included, not both- Self-vs-self combinations (
A-A) are excluded.
@combinations_with_replacement¶
- Given one set of Input, it generates the combinations of r-length tuples among them but includes self-vs-self conbinations.
- Uses formatter to generate unique Output names from components parsed from any parts of any specified files in all Input sets.
- For example, given Input called
A,BandC, it will generate:A-A,A-B,A-C,B-B,B-C,C-C
@permutations¶
- Given one set of Input, it generates the permutations of r-length tuples among them. This excludes self-vs-self combinations but includes all orderings (
A-BandB-A).- Uses formatter to generate unique Output names from components parsed from any parts of any specified files in all Input sets.
- For example, given Input called
A,BandC, it will generate:A-A,A-B,A-C,B-A,B-C,C-A,C-B