Latest Changes¶
Major Features added to Ruffus
Note
See To do list for future enhancements to Ruffus
version 2.6.3¶
21st April 2015
Bug fixes and minor enhancements¶
- @transform(..., suffix(“xxx”), output_dir = “/new/output/path”) works even when the ouput has more than one file (github)
- @subdivide( ..., suffix(“xxx”), output_dir = “/new/output/path”) works in exactly the same way as @transform(..., outputdir=”xxx”) (github)
- ruffus.drmaa_wrapper.run_job() works with python3 (github) Fixed issue with byte and text streams.
- ruffus.drmaa.wrapper.run_job() allows env (environment) to be set for jobs run locally as well as those on the cluster (github)
- New object-orientated style syntax works seamlessly with Ruffus command line support ruffus.cmdline.run (github).
version 2.6.2¶
12th March 2015
1) Bug fixes¶
pipeline_printout_graph()incompatibility with python3 fixed- checkpointing did not work correctly with @split(...) and @subdivide(...)
2) @transform `(..., suffix(“xxx”), output_dir = “/new/output/path”)¶
Thanks to the suggestion of Milan Simonovic.
@transform(..., suffix(...) ) has easy to understand syntax and takes care of all the common use cases of Ruffus.
However, when we need to place the output in a different directories, we suddenly have to plunge into the deep end and parse file paths using regex() or formatter().
Now, @transform takes an optional
output_dirnamed parameter so that we can continue to use suffix() even when the output needs to go into a new directory.# # input/a.fasta -> output/a.sam # input/b.fasta -> output/b.sam # starting_files = ["input/a.fasta","input/b.fasta"] @transform(starting_files, suffix('.fasta'), '.sam', output_dir = "output") def map_dna_sequence(input_file, output_file) : passSee example
test\test_suffix_output_dir.py
2) Named parameters¶
Decorators can take named parameters.
These are self documenting, and improve clarity.
Note that the usual Python rules for function parameters apply:
- Positional arguments must precede named arguments
- Named arguments cannot be used to fill in for “missing” positional arguments
For example the following two functions are identical:
Positional parameters:
@merge(prev_task, ["a.summary", "b.summary"], 14, "extra_info", {"a":45, "b":5}) def merge_task(inputs, outputs, extra_num, extra_str, extra_dict): passNamed parameters:
# new style is a bit clearer @merge(input = prev_task, output = ["a.summary", "b.summary"], extras = [14, "extra_info", {"a":45, "b":5}] ) def merge_task(inputs, outputs, extra_num, extra_str, extra_dict): passWarning
,extras=takes all the extras parameters (14, "extra_info", {"a":45, "b":5}) as a single list
- @split(...) and @merge(...)
- input
- output
- [extras]
- @transform(...) and @mkdir(...)
- input
- filter
- [replace_inputs or add_inputs]
- output
- [extras]
- [output_dir]
- @collate(...) and @subdivide(...)
- input
- filter
- output
- [extras]
- @originate(...)
- output
- [extras]
- @product(...), @permutations(...), @combinations(...), and @combinations_with_replacement(...)
- input
- filter
- [input2...NNN] (only for
product)- [filter2...NNN] (only for
product) where NNN is an incrementing number- tuple_size (except for
product)- [replace_inputs or add_inputs]
- output
- [extras]
3) New object orientated syntax for Ruffus¶
Ruffus Pipelines can now be created directly using the new
PipelineandTaskobjects instead of via decorators.# make ruffus pipeline my_pipeline = Pipeline(name = "test") my_pipeline.transform(task_func = map_dna_sequence, input = starting_files, filter = suffix('.fasta'), output = '.sam', output_dir = "output") my_pipeline.run()This new syntax is fully compatible and inter-operates with traditional Ruffus syntax using decorators.
Apart from cosmetic changes, the new syntax allows different instances of modular Ruffus sub-pipelines to be defined separately, in different python modules and then joined together flexible at runtime.
The new syntax and discussion are introduced here.
version 2.5¶
6th August 2014
1) Python3 compatability (but at least python 2.6 is now required)¶
Ruffus v2.5 is now python3 compatible. This has required surprisingly many changes to the codebase. Please report any bugs to me.
Note
Ruffus now requires at least python 2.6
It proved to be impossible to support python 2.5 and python 3.x at the same time.
2) Ctrl-C interrupts¶
Ruffus now mostly(!) terminates gracefully when interrupted by Ctrl-C .
Please send me bug reports for when this doesn’t work with a minimally reproducible case.
This means that, in general, if an
Exceptionis thrown during your pipeline but you don’t want to wait for the rest of the jobs to complete, you can still press Ctrl-C at any point. Note that you may still need to clean up spawned processes, for example, usingqdelif you are usingRuffus.drmaa_wrapper
3) Customising flowcharts in pipeline_printout_graph() with @graphviz¶
Contributed by Sean Davis, with improved syntax via Jake Biesinger
The graphics for each task can have its own attributes (URL, shape, colour) etc. by adding graphviz attributes using the
@graphvizdecorator.
This allows HTML formatting in the task names (using the
labelparameter as in the following example). HTML labels must be enclosed in<and>. E.g.label = "<Line <BR/> wrapped task_name()>"You can also opt to keep the task name and wrap it with a prefix and suffix:
label_suffix = "??? ", label_prefix = ": What is this?"The
URLattribute allows the generation of clickable svg, and also client / server side image maps usable in web pages. See Graphviz documentationExample:
@graphviz(URL='"http://cnn.com"', fillcolor = '"#FFCCCC"', color = '"#FF0000"', pencolor='"#FF0000"', fontcolor='"#4B6000"', label_suffix = "???", label_prefix = "What is this?<BR/> ", label = "<What <FONT COLOR=\"red\">is</FONT>this>", shape= "component", height = 1.5, peripheries = 5, style="dashed") def Up_to_date_task2(infile, outfile): pass # Can use dictionary if you wish... graphviz_params = {"URL":"http://cnn.com", "fontcolor": '"#FF00FF"'} @graphviz(**graphviz_params) def myTask(input,output): pass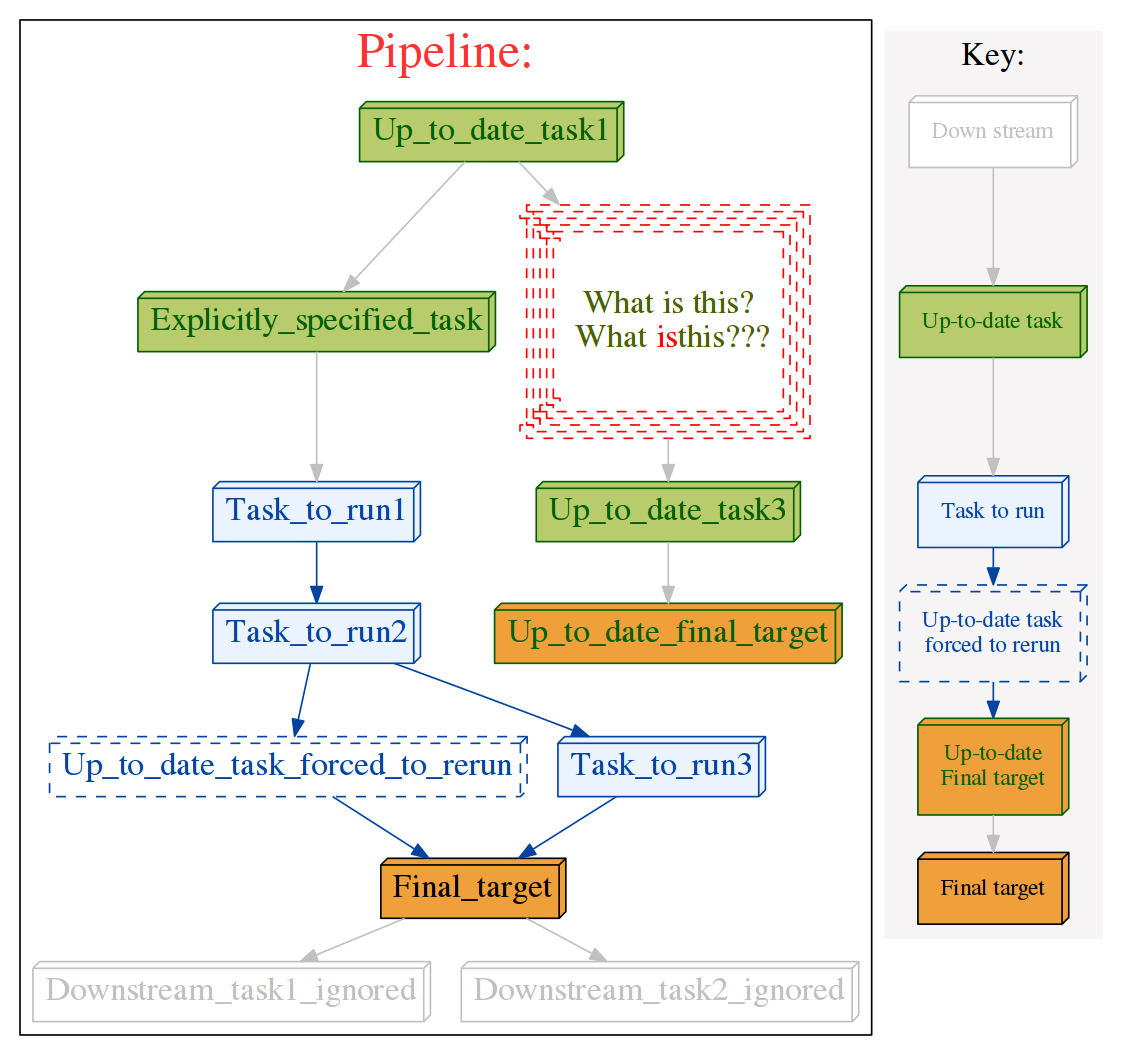
4. Consistent verbosity levels¶
The verbosity levels are now more fine-grained and consistent between pipeline_printout and pipeline_run. Note that At verbosity > 2,
pipeline_runoutputs lists of up-to-date tasks before running the pipeline. Many users who defaulted to using a verbosity of 3 may want to move up toverbose = 4.
- level 0 : Nothing
- level 1 : Out-of-date Task names
- level 2 : All Tasks (including any task function docstrings)
- level 3 : Out-of-date Jobs in Out-of-date Tasks, no explanation
- level 4 : Out-of-date Jobs in Out-of-date Tasks, with explanations and warnings
- level 5 : All Jobs in Out-of-date Tasks, (include only list of up-to-date tasks)
- level 6 : All jobs in All Tasks whether out of date or not
- level 10: Logs messages useful only for debugging ruffus pipeline code
- Defaults to level 4 for pipeline_printout: Out of date jobs, with explanations and warnings
- Defaults to level 1 for pipeline_run: Out-of-date Task names
5. Allow abbreviated paths from pipeline_run or pipeline_printout¶
Note
Please contact me with suggestions if you find the abbreviations useful but “aesthetically challenged”!
Some pipelines produce interminable lists of long filenames. It would be nice to be able to abbreviate this to just enough information to follow the progress.
- Ruffus now allows either
Only the nth top level sub-directories to be included
The message to be truncated to a specified number of characters (to fit on a line, for example)
Note that the number of characters specified is the separate length of the input and output parameters, not the entire message. You many need to specify a smaller limit that you expect (e.g.
60rather than 80)pipeline_printout(verbose_abbreviated_path = NNN) pipeline_run(verbose_abbreviated_path = -MMM)The
verbose_abbreviated_pathparameter restricts the length of input / output file paths to either
- NNN levels of nested paths
- A total of MMM characters, MMM is specified by setting
verbose_abbreviated_pathto -MMM (i.e. negative values)
verbose_abbreviated_pathdefaults to2For example:
Given
["aa/bb/cc/dddd.txt", "aaa/bbbb/cccc/eeed/eeee/ffff/gggg.txt"]# Original relative paths "[aa/bb/cc/dddd.txt, aaa/bbbb/cccc/eeed/eeee/ffff/gggg.txt]" # Full abspath verbose_abbreviated_path = 0 "[/test/ruffus/src/aa/bb/cc/dddd.txt, /test/ruffus/src/aaa/bbbb/cccc/eeed/eeee/ffff/gggg.txt]" # Specifed level of nested directories verbose_abbreviated_path = 1 "[.../dddd.txt, .../gggg.txt]" verbose_abbreviated_path = 2 "[.../cc/dddd.txt, .../ffff/gggg.txt]" verbose_abbreviated_path = 3 "[.../bb/cc/dddd.txt, .../eeee/ffff/gggg.txt]" # Truncated to MMM characters verbose_abbreviated_path = -60 "<???> /bb/cc/dddd.txt, aaa/bbbb/cccc/eeed/eeee/ffff/gggg.txt]"If you are using
ruffus.cmdline, the abbreviated path lengths can be specified on the command line as an extension to the verbosity:# verbosity of 4 yourscript.py --verbose 4 # display three levels of nested directories yourscript.py --verbose 4:3 # restrict input and output parameters to 60 letters yourscript.py --verbose 4:-60The number after the colon is the abbreviated path length
Other changes¶
- BUG FIX: Output producing wild cards was not saved in the checksum files!!!
- BUG FIX: @mkdir bug under Windows. Thanks to Sean Turley. (Aargh! Different exceptions are thrown in Windows vs. Linux for the same condition!)
- Added pipeline_get_task_names(...) which returns all task name as a list of strings. Thanks to Clare Sloggett
version 2.4.1¶
26th April 2014
- Breaking changes to drmaa API suggested by Bernie Pope to ensure portability across different drmaa implementations (SGE, SLURM etc.)
version 2.4¶
4th April 2014
Additions to ruffus namespace¶
Installation: use pip¶
sudo pip install ruffus --upgrade
1) Command Line support¶
The optionalRuffus.cmdlinemodule provides support for a set of common command line arguments which make writing Ruffus pipelines much more pleasant. See manual
2) Check pointing¶
Contributed by Jake Biesinger
See Manual
Uses a fault resistant sqlite database file to log i/o files, and additional checksums
defaults to checking file timestamps stored in the current directory (
ruffus_utilility.RUFFUS_HISTORY_FILE = '.ruffus_history.sqlite')pipeline_run(..., checksum_level = N, ...)
- level 0 = CHECKSUM_FILE_TIMESTAMPS : Classic mode. Use only file timestamps (no checksum file will be created)
- level 1 = CHECKSUM_HISTORY_TIMESTAMPS : Also store timestamps in a database after successful job completion
- level 2 = CHECKSUM_FUNCTIONS : As above, plus a checksum of the pipeline function body
- level 3 = CHECKSUM_FUNCTIONS_AND_PARAMS : As above, plus a checksum of the pipeline function default arguments and the additional arguments passed in by task decorators
- defaults to level 1
Can speed up trivial tasks: Previously Ruffus always added an extra 1 second pause between tasks to guard against file systems (Ext3, FAT, some NFS) with low timestamp granularity.
3) subdivide() (syntax)¶
- Take a list of input jobs (like @transform) but further splits each into multiple jobs, i.e. it is a many->even more relationship
- synonym for the deprecated
@split(..., regex(), ...)
4) mkdir() (syntax) with formatter(), suffix() and regex()¶
- allows directories to be created depending on runtime parameters or the output of previous tasks
- behaves just like @transform but with its own (internal) function which does the actual work of making a directory
- Previous behavior is retained:
mkdircontinues to work seamlessly inside @follows
5) originate() (syntax)¶
- Generates output files without dependencies from scratch (ex nihilo!)
- For first step in a pipeline
- Task function obviously only takes output and not input parameters. (There are no inputs!)
- synonym for @split(None,...)
- See Summary / Manual
6) New flexible formatter() (syntax) alternative to regex() & suffix()¶
- Easy manipulation of path subcomponents in the style of os.path.split()
- Regular expressions are no longer necessary for path manipulation
- Familiar python syntax
- Optional regular expression matches
- Can refer to any in the list of N input files (not only the first file as for
regex(...))- Can even refer to individual letters within a match
7) Combinatorics (all vs. all decorators)¶
- @product (See itertools.product)
- @permutations (See itertools.permutations)
- @combinations (See itertools.combinations)
- @combinations_with_replacement (See itertools.combinations_with_replacement)
- in optional combinatorics module
- Only formatter() provides the necessary flexibility to construct the output. (suffix() and regex() are not supported.)
- See Summary / Manual
8) drmaa support and multithreading:¶
- ruffus.drmaa_wrapper.run_job() (syntax)
- Optional helper module allows jobs to dispatch work to a computational cluster and wait until it completes.
- Requires
multithreadrather thanmultiprocess
9) pipeline_run(...) and exceptions¶
See Manual
- Optionally terminate pipeline after first exception
- Display exceptions without delay
10) Miscellaneous¶
- Better error messages for
formatter(),suffix()andregex()forpipeline_printout(..., verbose >= 3, ...)
- Error messages for showing mismatching regular expression and offending file name
- Wrong capture group names or out of range indices will raise informative Exception
version 2.3¶
1st September, 2013
@active_ifturns off tasks at runtimeThe Design and initial implementation were contributed by Jacob Biesinger
Takes one or more parameters which can be either booleans or functions or callable objects which return True / False:
run_if_true_1 = True run_if_true_2 = False @active_if(run_if_true, lambda: run_if_true_2) def this_task_might_be_inactive(): passThe expressions inside @active_if are evaluated each time
pipeline_run,pipeline_printoutorpipeline_printout_graphis called.Dormant tasks behave as if they are up to date and have no output.
- Command line parsing
- Supports both argparse (python 2.7) and optparse (python 2.6):
Ruffus.cmdlinemodule is optional.- See manual
- Optionally terminate pipeline after first exception
To have all exceptions interrupt immediately:
pipeline_run(..., exceptions_terminate_immediately = True)By default ruffus accumulates
NNerrors before interrupting the pipeline prematurely.NNis the specified parallelism forpipeline_run(..., multiprocess = NN).Otherwise, a pipeline will only be interrupted immediately if exceptions of type
ruffus.JobSignalledBreakare thrown.Display exceptions without delay
By default, Ruffus re-throws exceptions in ensemble after pipeline termination.
To see exceptions as they occur:
pipeline_run(..., log_exceptions = True)
logger.error(...)will be invoked with the string representation of the each exception, and associated stack trace.The default logger prints to sys.stderr, but this can be changed to any class from the logging module or compatible object via
pipeline_run(..., logger = ???)Improved
pipeline_printout()
@split operations now show the 1->many output in pipeline_printout
This make it clearer that
@splitis creating multiple output parameters (rather than a single output parameter consisting of a list):Task = split_animals Job = [None -> cows -> horses -> pigs , any_extra_parameters]File date and time are displayed in human readable form and out of date files are flagged with asterisks.
version 2.2¶
22nd July, 2010
Simplifying @transform syntax with suffix(...)
Regular expressions within ruffus are very powerful, and can allow files to be moved from one directory to another and renamed at will.
However, using consistent file extensions and
@transform(..., suffix(...))makes the code much simpler and easier to read.Previously,
suffix(...)did not cooperate well withinputs(...). For example, finding the corresponding header file (”.h”) for the matching input required a complicatedregex(...)regular expression andinput(...). This simple case, e.g. matching “something.c” with “something.h”, is now much easier in Ruffus.
- For example:
This is equivalent to calling:
compile(["something.c", "something.h", "common.h"], "something.o") compile(["more_code.c", "more_code.h", "common.h"], "more_code.o")The
\1matches everything but the suffix and will be applied to bothglobs and file names.For simplicity and compatibility with previous versions, there is always an implied r”1” before the output parameters. I.e. output parameters strings are always substituted.
Tasks and glob in inputs(...) and add_inputs(...)
globs and tasks can be added as the prerequisites / input files usinginputs(...)andadd_inputs(...).globexpansions will take place when the task is run.Advanced form of @split with regex:
The standard
@splitdivided one set of inputs into multiple outputs (the number of which can be determined at runtime).This is a
one->manyoperation.An advanced form of
@splithas been added which can split each of several files further.In other words, this is a
many->"many more"operation.
- For example, given three starting files:
- We can split each into its own set of sub-sections:
This is, conceptually, the reverse of the @collate(...) decorator
Ruffus will complain about unescaped regular expression special characters:
Ruffus uses “\1” and “\2” in regular expression substitutions. Even seasoned python users may not remember that these have to be ‘escaped’ in strings. The best option is to use ‘raw’ python strings e.g.
r"\1_substitutes\2correctly\3four\4times"Ruffus will throw an exception if it sees an unescaped “\1” or “\2” in a file name, which should catch most of these bugs.
Prettier output from pipeline_printout_graph
Changed to nicer colours, symbols etc. for a more professional look. @split and @merge tasks now look different from @transform. Colours, size and resolution are now fully customisable:
pipeline_printout_graph( #... user_colour_scheme = { "colour_scheme_index":1, "Task to run" : {"fillcolor":"blue"}, pipeline_name : "My flowchart", size : (11,8), dpi : 120)})An SVG bug in firefox has been worked around so that font size are displayed correctly.
version 2.1.1¶
- @transform(.., add_inputs(...))
add_inputs(...)allows the addition of extra input dependencies / parameters for each job.
- Unlike
inputs(...), the original input parameter is retained:from ruffus import * @transform(["a.input", "b.input"], suffix(".input"), add_inputs("just.1.more","just.2.more"), ".output") def task(i, o): ""- Produces:
Like
inputs,add_inputsaccepts strings, tasks andglobs This minor syntactic change promises add much clarity to Ruffus code.add_inputs()is available for@transform,@collateand@split
version 2.1.0¶
@jobs_limit Some tasks are resource intensive and too many jobs should not be run at the same time. Examples include disk intensive operations such as unzipping, or downloading from FTP sites.
Adding:
@jobs_limit(4) @transform(new_data_list, suffix(".big_data.gz"), ".big_data") def unzip(i, o): "unzip code goes here"would limit the unzip operation to 4 jobs at a time, even if the rest of the pipeline runs highly in parallel.
(Thanks to Rob Young for suggesting this.)
version 2.0.10¶
touch_files_only option for pipeline_run
When the pipeline runs, task functions will not be run. Instead, the output files for each job (in each task) will be
touch-ed if necessary. This can be useful for simulating a pipeline run so that all files look as if they are up-to-date.Caveats:
- This may not work correctly where output files are only determined at runtime, e.g. with @split
- Only the output from pipelined jobs which are currently out-of-date will be
touch-ed. In other words, the pipeline runs as normal, the only difference is that the output files aretouch-ed instead of being created by the python task functions which would otherwise have been called.Parameter substitution for inputs(...)
The inputs(...) parameter in @transform, @collate can now take tasks and
globs, and these will be expanded appropriately (after regular expression replacement).For example:
@transform("dir/a.input", regex(r"(.*)\/(.+).input"), inputs((r"\1/\2.other", r"\1/*.more")), r"elsewhere/\2.output") def task1(i, o): """ Some pipeline task """Is equivalent to calling:
task1(("dir/a.other", "dir/1.more", "dir/2.more"), "elsewhere/a.output")Here:
r"\1/*.more"is first converted to:
r"dir/*.more"which matches:
"dir/1.more" "dir/2.more"
version 2.0.9¶
Better display of logging output
Advanced form of @split This is an experimental feature.
Hitherto, @split only takes 1 set of input (tasks/files/
globs) and split these into an indeterminate number of output.This is a one->many operation.
Sometimes it is desirable to take multiple input files, and split each of them further.
This is a many->many (more) operation.
It is possible to hack something together using @transform but downstream tasks would not aware that each job in @transform produces multiple outputs (rather than one input, one output per job).
The syntax looks like:
@split(get_files, regex(r"(.+).original"), r"\1.*.split") def split_files(i, o): passIf
get_files()returnedA.original,B.originalandC.original,split_files()might lead to the following operations:A.original -> A.1.original -> A.2.original -> A.3.original B.original -> B.1.original -> B.2.original C.original -> C.1.original -> C.2.original -> C.3.original -> C.4.original -> C.5.originalNote that each input (
A/B/C.original) can produce a number of output, the exact number of which does not have to be pre-determined. This is similar to @splitTasks following
split_fileswill have ten inputs corresponding to each of the output fromsplit_files.If @transform was used instead of @split, then tasks following
split_fileswould only have 3 inputs.
version 2.0.8¶
- File names can be in unicode
- File systems with 1 second timestamp granularity no longer cause problems.
version 2.0.2¶
- Much prettier /useful output from pipeline_printout
- New tutorial / manual
version 2.0¶
Revamped documentation:
- Rewritten tutorial
- Comprehensive manual
- New syntax help
Major redesign. New decorators include
Major redesign. Decorator inputs can mix
- Output from previous tasks
- glob patterns e.g.
*.txt- Files names
- Any other data type
version 1.1.4¶
Tasks can get their input by automatically chaining to the output from one or more parent tasks using @files_re
version 1.0.7¶
Added proxy_logger module for accessing a shared log across multiple jobs in different processes.
version 1.0¶
Initial Release in Oxford